深入理解Presto
本文译自英文书籍<Presto: the definitive guide>Presto权威指南第四章,目前该书的中文翻译版尚未出版,本文摘出书中对Presto内部介绍比较深入的第四章,看过本文对全书感兴趣的同学,请购买英文原版,或等待中文翻译版出版。–2020/08/16
在简单了解过Presto和众多的使用场景、并且安装和开始使用她之后,你现在已经准备好了深入探索更多。
在本书的第二部分,你会了解到Presto内部的工作机制,并做好准备在生产环境去安装、使用、运行、调优等等。
我们讨论了关于连接数据源的更多细节,并且使用Presto的SQL语句、运算符、函数等来查询这些数据。
第四章 Presto架构
前边的章节,我们简单介绍了Presto,初步安装和使用了Presto。现在我们开始讨论Presto的架构。我们深入了解相关的概念,以使你能够了解更多Presto的查询执行模型、查询方案规划、基于代价的优化器。
在本章节中,我们首先讨论Presto高层次的架构组件。这很重要,因为会帮助我们大体的理解Presto的工作方式,尤其你准备自己安装和维护Presto的集群(这会在第五章介绍)。
在本章后边的部分,我们探讨查询执行模型时,会更加深入了解那些组件。这很重要,假如你需要诊断和调优慢查询(这会在第八章介绍),或者你准备向Presto开源项目贡献代码。
Coordinator和Worker两种角色
当你第一次安装Presto时,你只用了一台机器来运行所有的查询。但是,单机环境是远远达不到理想的规模和性能的。
Presto是一个分布式的SQL查询引擎,组装了多个并行计算的数据库和查询引擎(这就是MPP模型的定义)。Presto不是依赖单机环境的垂直扩展性。她有能力在水平方向,把所有的处理分布到集群内的各个机器上。这意味着你可以通过添加更多节点来获得更大的处理能力。
利用这种架构,Presto查询引擎能够并行的在集群的各个机器上,处理大规模数据的SQL查询。Presto在每个节点上都是单进程的服务。多个节点都运行Presto,相互之间通过配置相互协作,组成了一个完整的Presto集群。
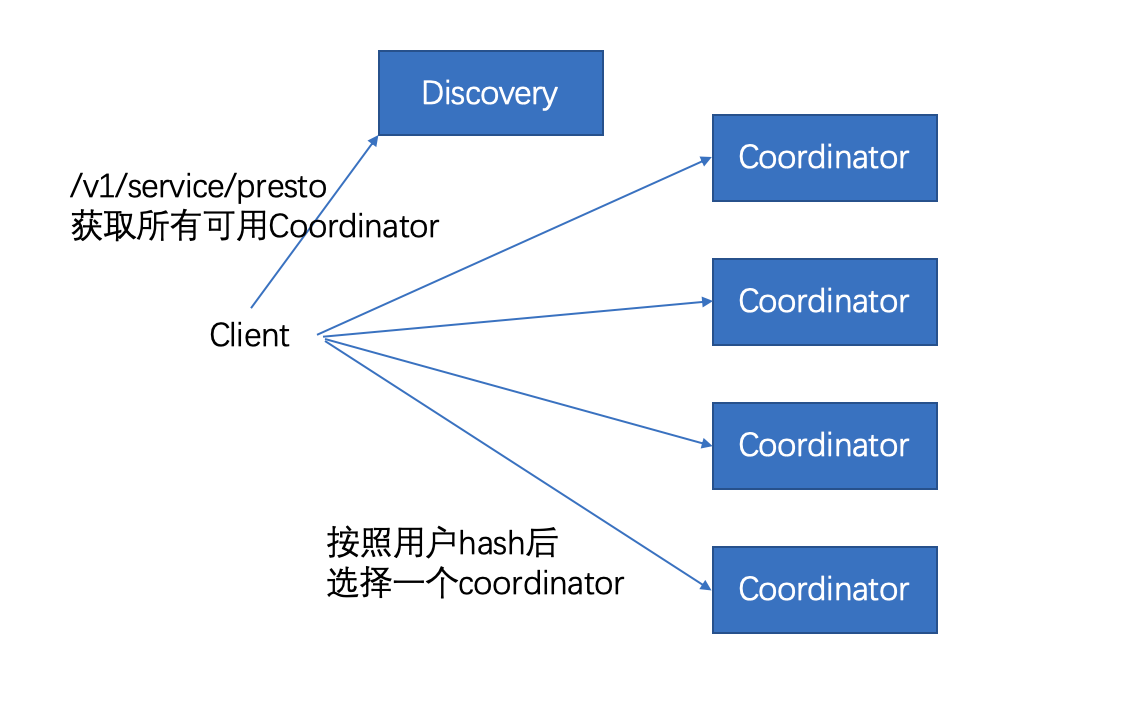
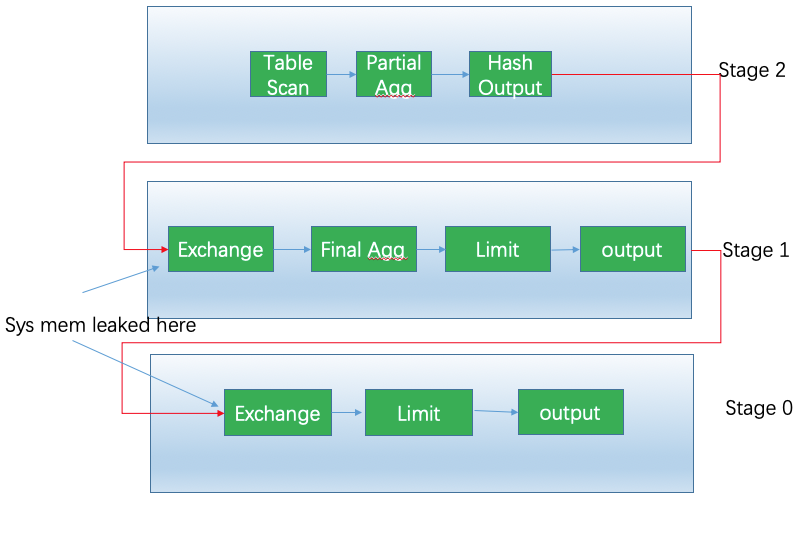
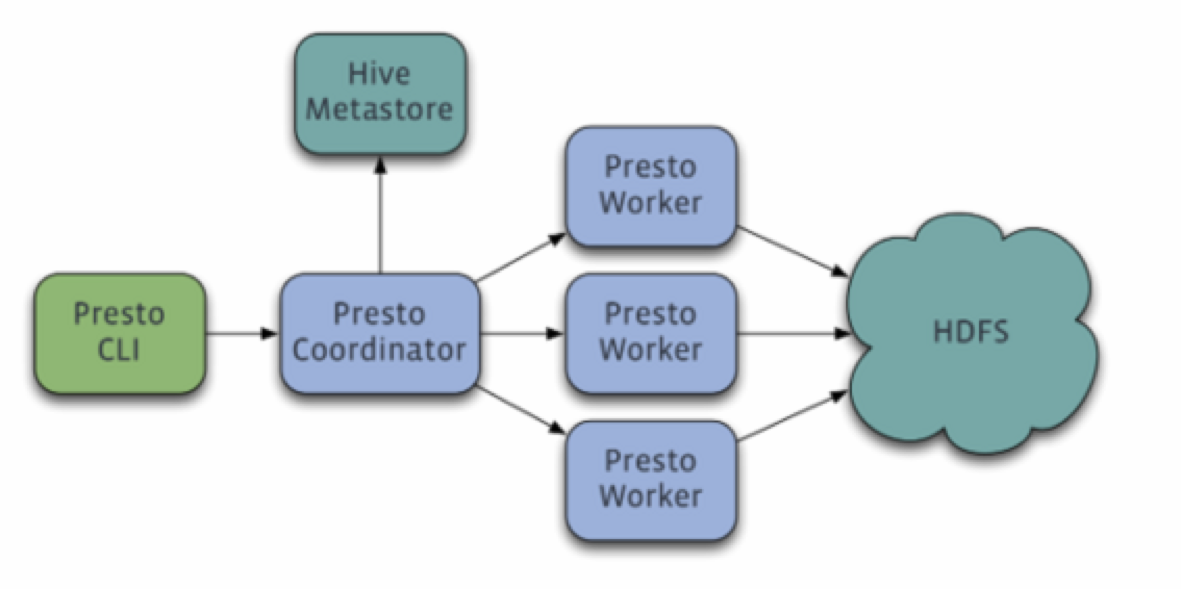
图4-1 展示了从宏观层面概括了Presto的集群组件:1个coordinator,多个worker节点。用户通过客户端连接到coordinator,可以短可以是JDBC驱动或者Presto命令行cli。
Coordinator是Presto上一个专门的服务,专门用来处理用户的查询请求,管理worker节点以执行查询。
Worker 节点则负责执行任务和处理数据。
Discovery服务通常跑在coordinator节点上,允许worker注册到集群信息中。
客户端、coordinator,worker之间的所有通信,都是用基于REST的HTTP/HTTPS交互。
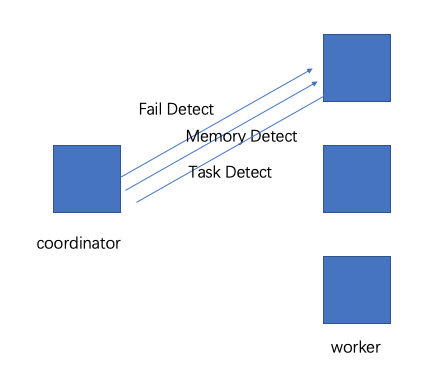
图4-2展示了集群内coordinator和worker之间,以及worker和worker之间的通信。coordinator向多个worker通信,用于分配任务,更新状态,获得最终的结果返回用户。worker之间相互通信,向任务的上游节点获取数据。所有的worker都会向数据源读取数据。
Coordinator
Coordinator的作用是:
- 从用户获得SQL语句。
- 解析SQL语句。
- 规划查询的执行计划。
- 管理worker节点状态。
Coordinator是Presto集群的大脑,并且是负责和客户端沟通。用户通过PrestoCLI、JDBC、ODBC驱动、其他语言工具库等工具和coordinator进行交互。Coordinator从客户端接受SQL语句,例如select语句,才能进行计算。
每个Presto集群必须有一个coordinator,可以有一个或多个worker。在开发和测试环境中,一个Presto进程可以同时配置成两种角色。
Coordinator追踪每个worker上的活动,并且协调查询的执行过程。Coordinator给查询创建了一个包含多阶段的逻辑模型,
图4-3展示了客户端、coordinator,worker之间的通信。
一旦接受了SQL语句,Coordinator就负责解析、分析、规划、调度查询在多个worker节点上的执行过程,语句被翻译成一系列的任务,跑在多个worker节点上。worker一边处理数据,结果会被coordinator拿走并且放到output缓存区上,暴露给客户端。一旦输出缓冲区被客户完全读取,coordinator会代表客户端向worker读取更多数据。worker节点,和数据源打交道,从数据源获取数据。因此,客户端源源不断的读取数据,数据源源源不断的提供数据,直到查询执行结束。
Coordinator通过基于HTTP的协议和worker、客户端之间进行通信。
图4-3 客户端,coordinator,worker通信,处理SQL语句
Discovery Service(发现服务)
Presto使用Discovery服务来发现集群内的所有节点。每个Presto实例在启动时就向Discovery服务注册,之后,周期性的发送心跳信号。这让coordinator获得一个实时的可用节点列表,并且使用这个列表来调度查询执行过程。
如果一个worker停止发送心跳信号,discovery服务触发宕机检测,这一个worker就不会调度新的任务了。
为了简化部署,避免运行额外的服务,Presto coordinator通常运行一个内嵌的discovery服务版本。
这个版本和Presto共享HTTP服务,因此使用同一个端口就足够。
Worker上关于discovery 服务的配置,通常指向coordinator的hostname和端口。
Workers
Presto的worker是Presto集群中的一个服务。它负责运行coordinator指派给它的任务,并处理数据。worker节点通过连接器(connector)向数据源获取数据,并且相互之间可以交换数据。最终结果会传递给coordinator。 coordinator负责从worker获取最终结果,并传递给客户端。
在安装过程中,要把discovery的主机名或IP地址告诉worker。worker启动后,会向discovery广播自己,之后才能在查询中调度任务。
Workers communicate with other workers and the coordinator by using an HTTP- based protocol.
Worker之间的通信、worker和coordinator之间的通信采用基于HTTP的协议。
图4-4展示了多个worker如何从数据源获取数据,并且合作处理数据的流程。直到某一个worker把数据提供给了coordinator。
图4-4 一个集群内的worker相互合作处理SQL和数据
基于Connector的架构
Presto计算和存储分离的架构核心,就是基于Connector(连接器)的架构。一个Connector提供了Presto访问任意一个数据源的接口。
每个Connector为底层的数据源提供了一层基于表的抽象接口。只要数据能够用表、列、行等形式,用P热宋体支持的数据类型,那么就可以创建出一个连接器,并通过这个连接器处理数据。
Presto提供了一套SPI接口,实现Connector就是要实现这些API。通过实现SPI接口,Presto就可以通过标准的操作连接任何数据源,并且在数据源上提供任何操作。这个连接器负责和数据源交互的细节。
每个Connector需要实现三种类型的API:
- 读取表/view/schema的metadata的操作。
- 提供逻辑上的数据分区,以方便Presto并行读和写。之所以说是逻辑上的,是因为Presto是计算存储分离的架构,Presto并不实际关心数据的实际存储位置。
- 读取的数据源和持久化数据的sink,把元数据从源格式转化成引擎期望的内存格式,或者把引擎的内存格式转化成存储的格式。
Presto提供了很多系统的连接器,例如HDFS/Hive, MySQL, Post‐ greSQL, MS SQL Server, Kafka, Cassandra, Redis等等。在第6章和第七章你会了解到多个连接器,会有越来越多的连接器出现。请查看Presto的文档,了解最新的连接器。
另外,Presto 的SPI接口为你提供了创建自定义连接器的能力。如果你需要访问的数据源,没有可用的兼容连接器,那么就需要创建自定义的链接起了。在这种场景下,我们强烈建议你了解更多Presto开源社区,获得我们的帮助,并且向社区贡献你的连接器。如果你在你的组织内有特殊的数据源,那么也需要一个自定义的连接器。这种方式,让Presto用户使用SQL来读取任意数据,实现真正的SQL-on-Anything。
图4-5 展示了Presto SPI包含的coordinator使用的metadata数据源,数据统计,数据位置信息,以及worker使用的数据流API。
Presto连接器是插件,每个server启动时加载这些插件。通过在catalog属性文件中配置特定参数,会从plugin目录加载。我们会在第六章探索更多相关信息。
Presto通过基于插件的架构,支持多种功能,除了连接器,插件会提供监听器、访问控制、函数和类型。
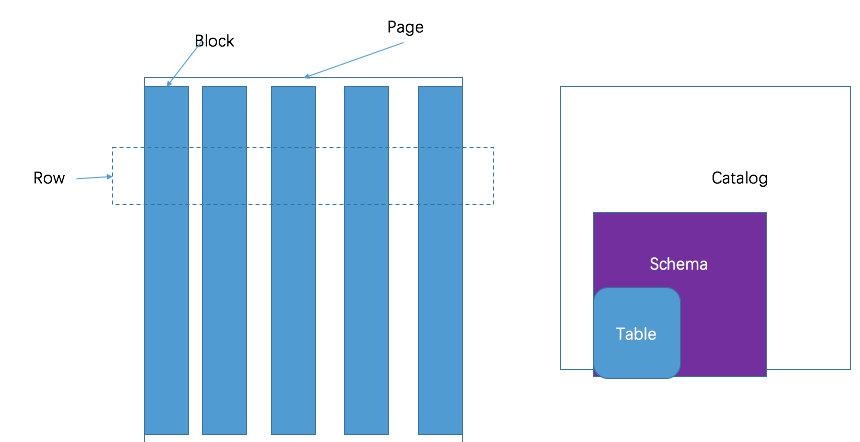
Catalogs(目录), Schemas(模式)和table(表)
Catalog、schema,table是Presto提供的三级数据管理结构。catalog对应连接器,schema对应一个数据源中的数据库,table对应数据库中的表。
Presto 集群使用基于连接器的架构来处理所有的查询。每个catalog配置使用一个连接器访问一个特定的数据源。数据源再catalog中暴露一个或者多个schema。每个schema包含若干个table(表),表中的每一行就是多列数据,每一列是不同的类型。在第八章会又更多关于catalog,schema,table的介绍。
Query Execution Model
Now that you understand how any real-world deployment of Presto involves a cluster with a coordinator and many workers, we can look at how an actual SQL query state‐ ment is processed.
查询执行模型
现在开始了解一下Presto现实世界中的开发。我们可以看一下一个实际的SQL语句是如何处理的。
理解执行模型会帮助你了解能够调优Presto性能的必要的基础知识。回忆一下,coordinator从终端用户那里接收SQL语句,使用方式包括使用ODBC/JDBC驱动的客户端软件。coordinator触发所有的worker去从数据源中读取数据,生成结果集合,并提供给用户。
首先我们深入一步探索一下coordinator内部发生了什么事情。当一个SQL语句提交给coordinator的时候,是普通的文本模式。coordinator接收文本,解析并且分析这段文本。然后它创建出一个执行计划。这个工作有是图4-6所描述的。查询执行计划从通常意义上概括了处理数据和返回结果的步骤。
图4-6 处理SQL语句,创建出一个查询计划
如图4-7所示,生成查询计划的过程,使用了metadata的SPI接口、数据的统计SPI接口。coordinator使用SPI来收集关于表的信息、链接数据源的信息等等。
图4-7 服务提供商接口用于query的规划和调度。
coordinator使用metadata SPI接口来获取表、列、类型的信息。这些信息用于校验Query的语义是否正确,执行语句的类型检查、安全检查。
统计SPI接口用于获取关于行数的信息、表大小的信息。这些信息可以在生成执行计划的阶段用来做基于代价的查询优化。
数据位置的SPI接口在创建分布式执行计划的过程中被用到。这些信息用来生成表的逻辑上的split。split是并行执行时最小的调度单元。
分布式的执行计划扩展了简单查询计划。简单查询计划包含了一个或者多个stage(阶段)。 简单查询计划会分割成计划段。一个stage描述的就是一个计划段(fragment)在执行时刻,包含了stage的计划段中所有的任务。
coordinator分割开整个plan,从而有效的利用集群的并行度加速整体查询的速度。由于有多个stage,导致会出现一个依赖树。stage的个数取决于查询的复杂度。例如,查询的表、返回的列。join语句,where条件,group by运算,和其他的SQL语句,都会影响stage的个数。
图4-8描述了逻辑执行计划是如何转换成分布式查询计划的。
图4-8 查询计划转化成分布式查询计划
分布式查询计划定义了定义了stage,以及在Presto集群中执行query的方法。coordinator用它来做进一步的规划、调度task到worker节点上。 一个stage包含了一个或多个task。典型的,会引入很多task,每个task处理一小片数据。
如图4-9所示,coordinator指定task到worker节点上。
图4-9 coordinator所做的任务管理。
数据处理的单元被称为split。split描述从底层读取和处理的一段数据。split是并行计算的最小单元,是任务分配的单元。连接器能够做的操作依赖于底层的数据源。
例如,hive连接器用以下信息描述split:文件的路径、所取数据的offset、length。
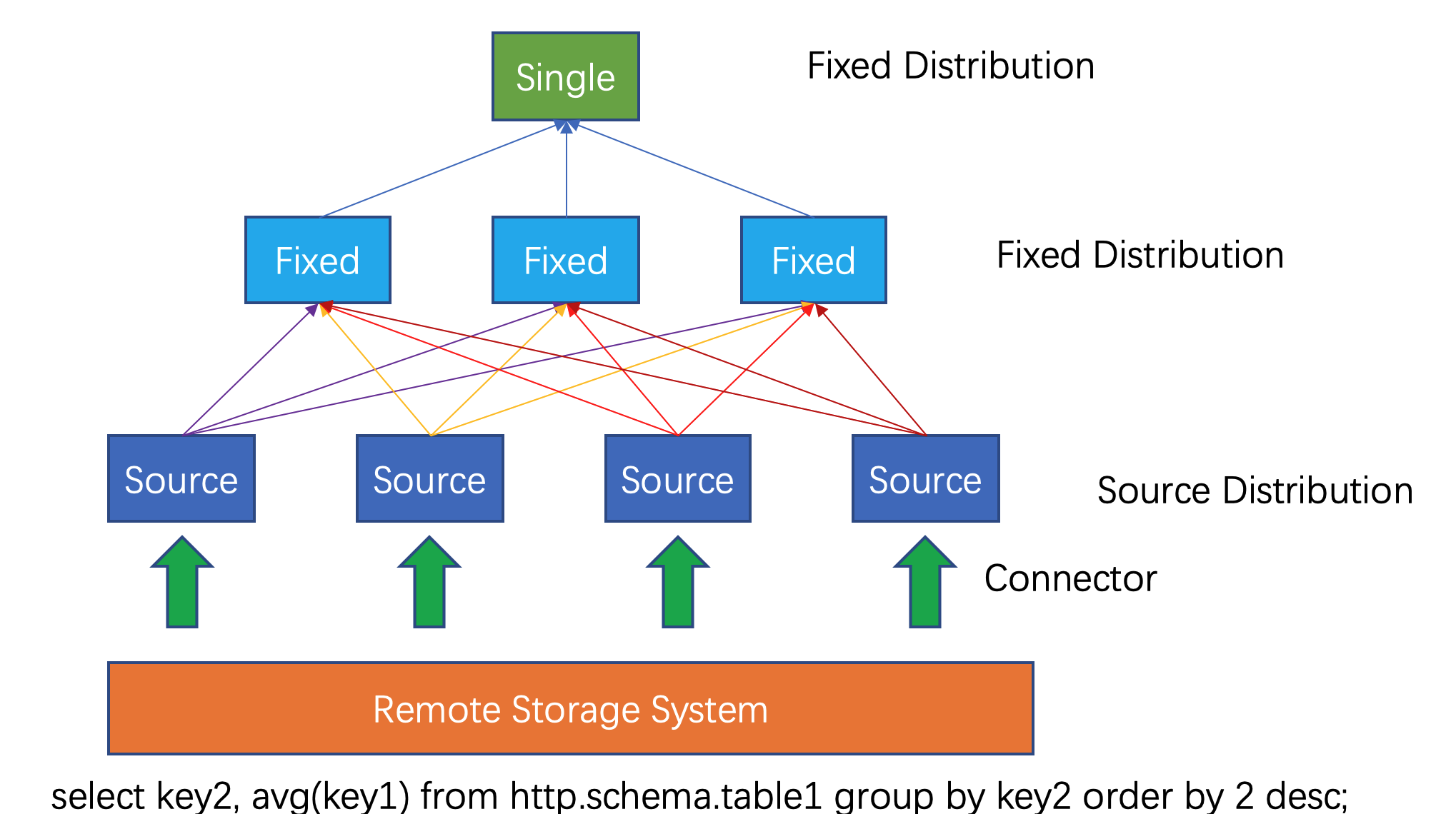
数据源阶段的task以page(页)这种格式生成数据。page是以列式格式存储的多行数据集合。page数据通过stage的依赖关系,流向下游的stage。 不同的stage之间通过exchange运算交换数据,这种运算符从上游的stage中读取数据。
source task使用数据源的SPI来从底层的数据源中获取数据,数据以page的形式流向Presto,流过整个引擎。各个运算符根据自己的语义处理和产生数据。例如filter运算符丢掉一些数据,project运算发产生新的列数据。task内部的运算符之间的顺序成为流水线。流水线上最后一个运算符把他的输出放到ouptut缓存区。下游的exchange 运算符从这个缓冲区获取数据。不同worker之间的运算符是并行执行的。
图4-10 不同的split中的数据在task之间交换,在不同的worker上处理。
所以,task就是计划段(plan fragment)分配给worker运行时的称呼。当一个task创建出来后,它为每一个split初始化一个driver。每个driver初始化一个流水线的operator,然后处理一个split的数据。一个task可能会使用多个driver,取决于Presto的配置。一旦所有的driver都完成了,数据被传递到了下一层split,driver和任务结束了他们的工作,之后被销毁。
图4-11, 一个task中并行的driver,处理输入和输出的split
一个运算符处理输入的数据,并且向下游的运算符输出数据。常见的运算符包括表扫描运算符,过滤,join,聚合计算。一系列运算符构成operator的流水线。举个例子,一个流水线包含了一个扫描运算符读取数据,然后过滤数据,最后执行局部聚合。
为了处理一个查询,coordinator通过连接器的metadata创建了一组split。通过这一组split,coordinator开始调度task到机器上来采集数据。在查询执行阶段。coordinator追踪所有的可用split和他们的位置信息。一个task处理完成数据后,会产生更多的下游split。coordinator持续的调度任务,直到没有split需要处理。
一旦所有的split处理完成,所有的数据都可用,coordinator会把数据结果提供给客户端。
查询计划
在深入了解Presto逻辑执行计划生成器和基于代价的优化器如何工作之前,我们先限定一下我们考虑范围。这里提供了一个样例,来帮助我们探索逻辑执行计划的生成过程。
1 | 样例 4-1. Example query to explain query planning |
先了解一下这个SQL的目的。
- SELECT使用了三个表,隐式定义了一个CROSS join,跨越了三张表格。
- WHERE条件获得满足条件的行。
- group by聚合计算,group by的key是regionKey,nationKey。
- 一个子查询,SELECT name FROM region WHERE regionkey = n.regionkey向region表中读取region的名称。请注意这个查询是相关联的。
- 一个oder by语句,按照orders_sum 倒序排序。
- limit限制5行,表示返回oders_sum最多的5行返回给用户。
解析和分析
在query执行之前,需要先解析和分析。关于SQL的语法相关的规则会在第八章和第九章介绍。presto检验语法规则,然后分析这个查询。
- 识别表名称:表在catalog和schema内,所以多个表可以又相同的名称。
- 识别列名:一个带限定的列名
orders.totalprice唯一只想了orders表的totalprice列。但是SQL可以通过只引用列名totalprice,也可以确认是属于哪个表的。Presto通过分析就可以找到列名是属于哪个表。 - 识别row列内的字段。字段
c.bonus可以表示c表的bonus列,也可以表示c这一列(row类型)内的bonus字段。Presto的分析器决定应该是哪种情况,一旦有模糊问题,那么优先认为是表中的列名,以避免歧义。分析的时候,需要了解SQL语法的作用于和可见规则。采集到的信息会在之后的planning阶段用到,因此planer无需再次了解查询语言的作用域规则。
如上文所述,Query分析器有一个非常复杂和交叉剪枝的责任。他的角色是属于技术性的,对于终端用户而言,只要查询语法是对的,就看不到这部分解析的过程。只有查询违反了SQL语言的规则、没有权限等错误情况下,用户才能意思到Query解析器的存在。
一旦query分析完成,所有的符号都解析出来,Presto会进入下一步,就是planning(生成逻辑执行计划)
初步的查询执行计划
查询执行计划可以看成是一个程序,这个程序可以产出查询结果。SQL是一种声明式语言,用户写一个SQL来指定要查询的数据。和命令式程序不同,用户不必指定怎么处理数据才能获得结果。Query的计划器和优化器可以决定处理数据的过程。
处理数据的步骤的顺序就是查询逻辑执行计划。理论上,有很多种逻辑执行计划可以产生相同的查询结果,但是不同的逻辑执行计划的性能是非常不同的。所以就需要逻辑计划生成器和优化器来决定一个最佳的逻辑执行计划。可以产生相同结果的执行计划可以称为等同执行计划。
我们来看一下样例4-1中的查询。最直接的逻辑执行计划就是直接翻译SQL的语法结构。解析出来的执行计划如样例4-2所示。逻辑执行计划是一个树结构,执行时从叶子节点开始,逐层向上处理树结构。
1 | 样例4-2 手工生成的,非常直接的逻辑执行计划 |
逻辑执行计划中的每个元素都可以直接的,用命令式的风格来实现。例如TableScan访问底层的表,返回表中的所有的行。过滤器接收行,应用一个过滤条件,只保留满足条件的行。Cross join操作两个数据集,生成两个数据集的组合。或许可以把某个数据集保存在内存中,这样不必多次访问底层的存储系统。
接下来我们看一下这个查询逻辑执行计划的计算复杂度。如果不知道所有实现的细节,就没办法评估复杂度。但是,我们可以假定,最小的复杂度就是数据集的大小。因此我们用O表示法。如果N,O,C,R代表nation,orders,customer,region的表的行数。这样我们可以观察到下边的内容:
- TableScan[orders]读取orders表,返回O行,所以复杂度是Ω(O)。类似的其他的两个tableScan的复杂度是 Ω(N),Ω(C)。
- TableScan[nation]和TableScan[orders]上的CrossJoin综合了nation和orders的数据,所以复杂度是 Ω(N × O)。
- 再上层的CrosssJoin,两个数据集的大小分别是N*O和C,所以复杂度是Ω(N × O × C)。
- 底层的TableScan[region]复杂度是Ω(R)。但是,由于后续的Join,这个tableScan被调用了N次,N是从聚合计算中返回的行数。所以这个运算复杂度是 Ω(R × N) 。
- Sort运算符需要对N行进行排序,所以他的时间复杂度最小是N*log(N)
上述运算符是代价最大的,所以在这里先忽略其他的运算符。这里的总的代价最小是Ω[N + O + C + (N × O) + (N × O × C) + (R × N) + (N × log(N))],无需直到表的相对大小,这个公式可以简化成Ω[(N × O × C) + (R × N) + (N × log(N))].假设region是最小的表,nation是第二小的表,我们可以忽略第二部分和第三部分,获得一个简化的结果Ω(N × O × C)。
关系代数的公式到此为止,接下来我们看看这在实际应用中的意义。举个例子,假如一个热门的购物网站有1000万客户,分布在200个国家,总共下单了10亿次订单。两个表的Cross Join需要物化20,000,000,000,000,000,000行数据。对于一个中等的100个节点的集群,每个节点处理速度是100万行/秒,则需要63个世纪才能处理完所有的数据。
当然,Presto不会去傻乎乎的处理这样一个图样图森破的执行计划。但是这样一个图样图森破的执行计划有他的用处。初始化的执行计划扮演了一个桥梁的作用,连接起SQL语法及其所代表的语义规则,和查询优化。查询优化的作用就是把这样一个原生的执行计划转化成一个效果对等的计划,但是执行上尽可能的快,至少能用有限的Presto资源在可接受的时间延时内完成。 接下来我们探讨一下查询优化器是如何获得这样一个优化目标的。
逻辑执行计划优化的规则
在这一章节,我们来看一下Presto用到的优化规则。
1.谓词下推
谓词下推可能是唯一最重要的优化规则和最容易理解的规则。他的目标就是把过滤条件下推到离数据源越近越好。因此,数据的规模会在更早的执行阶段完成。在我们的案例中,过滤会转换成一个简单过滤和内连接,之下是同样的CrossJoin条件。变化后的执行计划如下所示4-3。没有发生变化的部分在这里忽略调。
1 | 样例4-3,CrossJoin和Filter变成一个InnerJoin |
原来更大的Join变成了一个InnerJoin,保持相同的条件。我们暂时不深入细节,假设这样一个Join可以在分布式系统中高效的执行,计算复杂度等同于处理的行数。这意味着谓词下推至少把Ω(N × O × C) CrossJoin 实现变成了一个Θ(N × O)。
但是,谓词下推不能优化nation和orders表之间的CrossJoin,因为两个表之间没有直接的条件关联。这正是消除CrossJoin方法能发挥作用的地方。
2. 消除CrossJoin
在没有CBO(基于代价的优化器),Presto 根据表出现在select中的顺序来进行join。一个重要的例外是,要join的表没有任何关联条件,这就是Cross Joinn。在实际案例中,crossjoin并不符合需求,Join出来的大部分行在之后都会过滤掉。但是cross join有太多的工作以至于可能完不成。
消除Cross join把要join的表的顺序进行重排,目的是减少cross join的数量,最好是减少到0。在没有表的相对大小信息情况下,处理Cross join消除, table重排也可以做,所以用户可以掌控这一切。所以消除Cross Join的案例参考样例4-4. 现在两个Join都是inner join,促使Query的整体代价变成Θ(C + O) = Θ(O).其他部分没有发生变化,所以整体的查询计算代价是Ω[O + (R × N) + (N × log(N))]。当然O所代表orders表的行数是决定性因素。
1 | Example 4-4. 重排join消除cross join |
3. TopN
通常, 如果一个query包含了limit语句,那么前边必然跟着一个order by语句。否则,如果没有order by排序,那么SQL返回的结果是随机的,你多次查询,结果会不同。带上order by ,则会保证查询的顺序和结果。
当执行一个查询是,Presto可以对所有的行进行排序,然后取最前边的几行。这种做法的复杂度是Θ(row_count ×log(row_count)),内存复杂度是Θ(row_count)。 这种排序整个结果,而只取部分结果的做法,明显非常浪费,不是最佳做法。因此,一个优化规则把order by 和limit联合语句优化成了TopN逻辑计划节点。在query执行阶段,TopN在一个堆结构中保存一定数目的行数,当流式读取数据时,更新这个堆结构。这让时间复杂度降低到了Θ(row_count × log(limit)) ,内存复杂度降低到了Θ(limit)。 整体的查询复杂度是Ω[O + (R × N) + N]。
4. 局部聚合
Presto没必要把orders表所有的行都传递给join,因为我们不是对每个单独的订单感兴趣。我们的样例查询,计算的聚合是堆每个nation计算totalprice的sum值,所以可以先预聚合,如样例4-5所示。我们通过聚合数据,减少了流入下游Join节点的行数。结果不是完整的,这也是为何被成为预聚合。但是数据的规模有可能被降低,显著的提升查询性能。
1 | - Aggregate[by nationkey...; orders_sum := sum(totalprice)] |
对于并行计算,预聚合可以以不同方式完成,也称为『局部聚合』。下文我们展示一个简化的执行计划,当然和实际的EPLAIN计划相比,有一些不同。
实现规则
上文提到的规则是优化规则,规则的目标是减少查询处理时间,内存用量,网络交换的数据量。但是,即使是我们的样例查询,初始的逻辑执行计划还包含一些尚未实现的操作: lateral join。 在下一章节,我们看一下Presto怎么实现这种类型的操作。
1. lateral join解耦
lateral join可以实现成一个for-each循环,遍历一个数据集的每一行数据,然后执行另一个查询。这样的实现是有可能实现的,但这不是Presto处理的方式。其实,Presto解耦这样的子查询,上拉所有的相关条件,组成一个left join。在SQL语义中,这对应下边的查询转换。
1 | SELECT |
上述查询转化成:
1 | SELECT |
尽管我们可以这样交换规则,但是谨慎的、堆SQL语义非常了解的读者知道,上边的两个语句不是完全对等。如果region表中有regionkey重复的条目,第一个查询会失败,第二个查询不会失败。第二个查询虽然不会失败,但是会产生更多的结果。基于这个理由,lateral join解耦使用join之外的两个元素。第一,给原表的行编码,以使他们可区分。第二,join之后,检查一下是否有任何行是重复的。如样例4-6所示。如果检测到重复,查询会失败,以保护原始的查询语义。
1 | 样例4-6 lateral join解耦需要额外的检测 |
2. Semi-Join(In)解耦
一个子查询不仅可以用来获取信息(如上边lateral join样例),也可以用IN谓词来过滤行。实际上,IN谓词可以用来在filter中(WHERE 语句), 或者在一个projection中(SELECT 语句),当你在projection中用一个in语句的时候,他不仅仅是一个简单的bool 判断的运算符,例如exists。实际上,in谓词可以判定成true,false,null。
让我们考虑一个查询场景,找到那些顾客和物品供应商来自同一个国家的订单,如样例4-7所示。这样的订单可能存在,例如,我们想节省物流费用,减少物流环境的影响,可以直接把物品从供应商处寄给顾客,省略掉分拣中心。
1 | SELECT DISTINCT |
当然,上述需求可以通过lateral join实现,可以实现成一个循环,遍历外层查询的每一行,然后子查询获得所有的供应商的所有的国家,多次调用即可。
但是我们有更好的做法,Presto解耦子查询,去除关联条件后,子查询计算一次,然后回来和外层的查询通过关联条件进行join。棘手的地方在于join要保证不能产生多行结果(所以要用到去重的聚合)。这种转换正确的保留了in谓词的三值逻辑。
在这个案例中,去重的聚合计算使用了和join相同的分区,所以可以以流式的方式执行。不需要在网络上交换数据,同时使用了最少的内存。
本文总结
以上介绍了Presto的一些基础处理操作,在下一篇文章中,我们将介绍一些高端话题:基于代价的优化器(CBO).