Procella@Youtube 把计算加速玩到极值的实时计算引擎
Procella的应用场景
在youtue内部,在数据分析领域有4个方面的应用场景:
- 报表和大盘:1000亿数据/天,要求在10ms的延时内完成近实时的计算,主要的计算类型过滤/聚合/set/join
- 内嵌的统计指标,例如视频的浏览人数等等,特点是数据不停的变化,每秒上百万次查询。
- 时序数据监控:特点是query固定,数据量小,可以下采样,旧数据过期,以及一些特有的查询例如估算函数和时序函数。
- Ad hoc查询:提供给数据科学家,BI分析师等使用的,特点是query比较复杂,且不可预测,要求延时在秒级别处理一万亿行数据。
老的解决方案和挑战
针对以上需求,在Youtube内部原来有这几种解决方案:
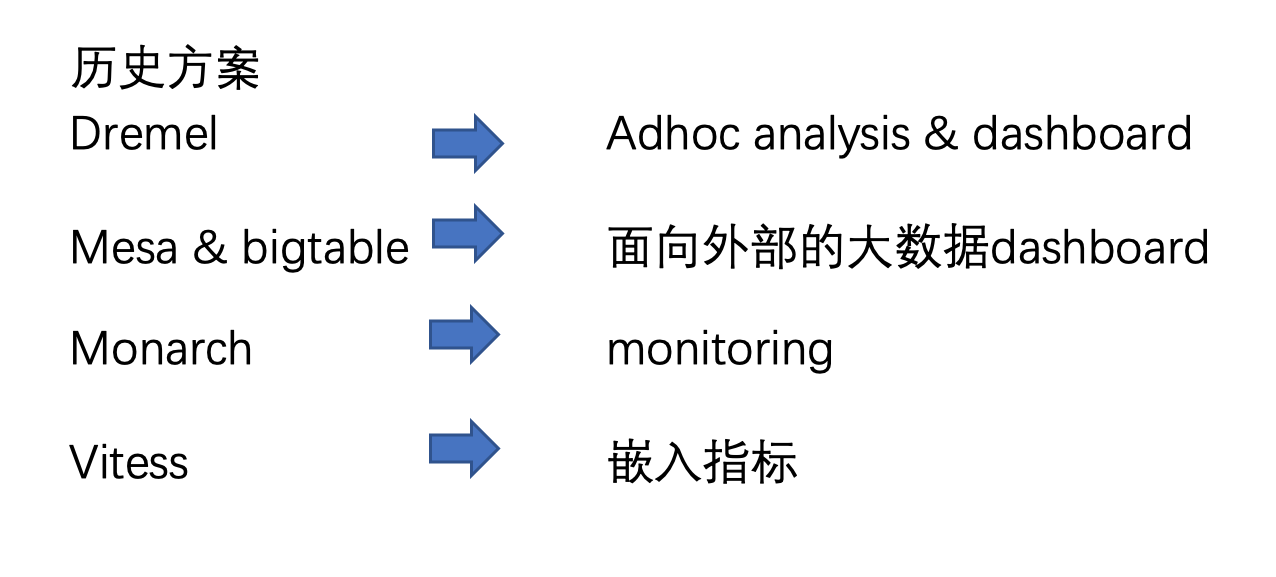
采用以上方案,有以下挑战:
- 数据需要在多个系统之间流转,复杂度高。
- ETL打开的维护开销。
- 不同系统之间的数据一致性和数据质量差别。
- 不同系统都有学习成本,有些系统不支持SQL全集。
- 一些底层组件性能查,可用性和扩展性无法满足需求。
Procella的特点
为了解决上述挑战,Youtube引入了Procella, Procella有如下特点:
- 支持标准SQL,并且做了一些扩展,支持估算函数、嵌套类型、UDF等。
- 高扩展性,计算和存储解耦,两者都可以无限扩展。
- 高性能,引用最新的计算计算,支持百万qps,毫秒级别响应。
- 数据freshness,支持batch和stream两种写入模式,原生支持lambda架构。
Procella的性能
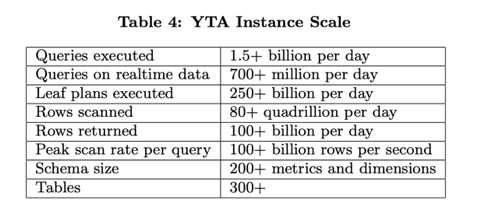
Procella 15亿查询/天,一条扫描8E16行数据/天,返回1000亿行/天
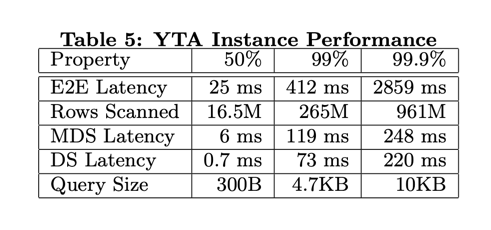
延时的中位数是25毫秒,p999为 2.8秒,也就是说99.9%的查询在2.8秒内查询完成。
在毫秒级别晚上大规模数据的计算,Procella是如何做到的呢?下文将来揭秘。
Procella的架构
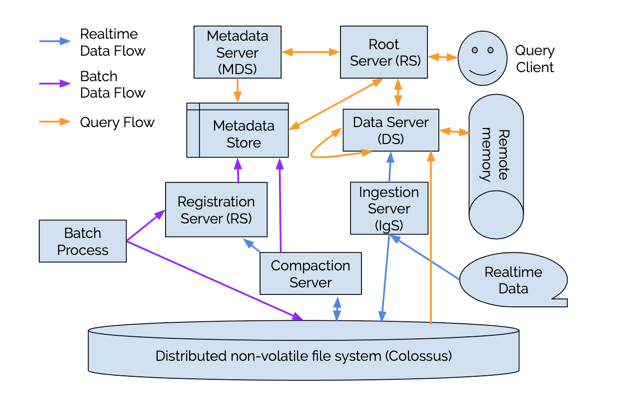
Procella采用计算和存储解耦的架构:
数据存储在分布式文件系统Colossus上,类似hdfs/盘古。
计算任务跑在由borg维护的机器上。
数据写入
Procella数据写入有两条链路:
- 右侧的realtime数据,写入Ingestion Server,Ingestion Server把数据存储在Collossus上,与此同时,会把数据写一份到DataServer上(为啥呢? DataServer是负责计算的,发送到DS是为了做缓存,更有效的利用内存数据,因为Youbute的查询大部分依赖最近的数据,下文在查询加速上会提到该点)
- 批量导入节点,采用离线的方式,离线通过MapReduce任务生成满足格式要求的文件,把文件写到Colossus上,然后再把文件信息注册到RegistrationServer上,这样避免了突然导入大量数据对系统的负载。
数据模型
Procella的数据分成两部分,分别是Data和metadata。
Procella采用的是表模型,存储格式是Artus的列式格式,数据存储在分布式文件系统Colossus。计算由DataServer完成,由于计算和存储是解耦的,所以同一份数据可以由多个DataServer来做计算。
MetaData包含了用于辅助计算的一些结构,称为secondary structure。包括zonemap(min,max等信息), bitmap(倒排索引), bloom filter, 分区, 排序键等。 metadata从列存储的文件头中读取,或者ds在计算query时生成。 metadata和data存储位置不同,是存储在bigtable或spanner上的。
通过DDL的形式管理表,DDL发送到Root Server(query入口),管理表的机制有分区、排序、constraint, 写入方式等。对于实时表,还支持生命周期管理,下采样,compact。
在compaction阶段,允许通过使用user defined sql 来处理数据,例如过滤,聚合,生命周期管理等。相当于在compaction阶段来做etl。
查询
好了,到了最关键的查询阶段, 首先看一下查询的流程。
在上文的架构图中,可以看到Procella的查询流程。
- client发起query,到达RootServer。
- RootServer解析sql, 优化plan
- 分配计算任务到DataServer上。
- DataServer读取数据(大部分在内存中, 少量读远程分布式存储),计算。
- 最终结果通过。
在整个查询,例如语法解析,plan 优化,计算,都是常见的流程。 而Procella的亮点在于做了相当多的优化手段,以加速计算,实现毫秒级别的响应。下文介绍具体有哪些优化手段。
查询优化
DataServer端的优化
- 读取数据时,数据有三种来源,local mem,缓存在本地内存中的数据;remote file,存储在分布式存储系统上的文件,remote memory,通过RDMA技术读取远程DataServer内存中的内容。RDMA 技术可以比RPC/http技术更快的从其他机器内存中读取数据。
- 尽可能的把计算任务下推到数据节点,例如filter,agg,project,join,能下推到最底层就下推到最底层,这样可以最大限度的减少数据的读取量,以及计算量。
- 在计算时,以encoding-native的方式读取,什么是encoding-native呢?就是算法感知编码格式,例如dictionary编码,在filter时,先从字典中filter出来要的key id,再到数据编码中找对应的id。
- 数据交换用stubby(一种grpc协议), shuffle用RDMA协议。
Cache
上文的架构图中提到,Procella是一种计算和存储分离的架构,这种数据和计算分离的方式,虽然能带来规模上的扩展性,但是也给单次查询带来了overhead。Procella时怎么做的呢?Procella通过大量的使用缓存来达到加速的目的,避免从远程读取数据。
- file metadata cache:数据存储在分布式存储上,每次读取文件,首先要向master获取文件真实存储的机器,然后再取对应的机器上读取数据。每次调用必然带来开销,因此在内存中维护了block -> file的handle信息。这样就比不要每次都从远程读取了,节省了rpc的开销。
- header cache, 列存文件的header中记录了文件的meta,每次读取这些meta要打开文件。IO的开销很大,因此在内存中采用lru来缓存这些header。
- Data Cache, 部分数据缓存在内存中,以加速计算,前文提到,实时数据流会有一份发送到内存中。
- 在内存中的数据格式,和磁盘上是一样的。这意味着,数据以encoding的模式放在内存中,不会反序列化,在计算时也直接操作encoded数据。这样节省了反序列化的开销。
- 一些计算复杂的output,也会缓存下来,还有一些metadata,例如bloom filter也会缓存下来。
- metadata的缓存,上文提到的各种secondary structure,都会缓存在内存中。
- 亲缘调度,由于大量的使用了缓存,也就意味着,在调度时,跟这份数据相关的,都需要尽量调度到同一个机器上,避免调度上颠簸,提高缓存命中率。
- 由于缓存技术以及很高的缓存命中率,使得procella在使用上彻底变成了一个内存数据,2%的数据保存在内存中,换取了99%的file handle命中率和90%的data 命中率。当然这个命中率可能是跟youtube特有的使用模式相关的,在youtube有大量的计算最新数据的需求。
- 对于metadata的缓存,从存储load到内存时,会编码成encoding模式,减少内存的使用率。
特有的列式格式Artus,启发式的encoding
youtube在设计列式存储时,需求有两个,分别是
- lookup,随机seek某些行数据。
- range scan, 扫描大块的数据。
存储上采用各种encoding 模式,不用压缩数据。这意味着读取时,也不用解压缩。
同时在计算时,直接在encoding模式智商进行,避免了反序列化。
encoding之后的数据大小和压缩后的大小基本接近,也就是说在存储空间上不是问题。
procella采用启发式的编码方式,根据数据特征进行特殊编码
- 在编码时进行多次扫描数据,第一次扫描采集轻量级信息,例如distinct value,min,max, sort order, 根据这些信息决定最佳的encoding模式。
- encoding模式包括dictionary encoding, rle, delta等。
- 如何动态的选择编码格式呢? 根据上边采集的信息,同时也会评估每一种encoding的压缩率和速度,决定最终的编码方式。
- 在查询时,可以实现O(logn)级别的搜索,O(1)seek到具体行。当然对于变长类型(例如字符串), 可以给每一段数据记录skip block信息,方便查找时快速跳过某些block。
- file和column header中记录了多种meta,例如sorting, min,max,encoding,bloom filter等用于剪枝,减少不必要的IO。例如通过pk来分文件,减少文件的读取次数。
- 通过倒排索引来加速in类计算。通常in类操作,可以变成join计算,或者逐个比较每个值,这种处理方式的性能是很差的,join计算是SQL里边的老大难题了,而逐个比较,时间复杂度在O(m*n)级别。而通过倒排索引,可以直接在O(1)级别知道是否存在对应的数据。
- 在数据摄入时,存储过程会针对计算做一些优化,比如分配partition, 部分aggregation预计算,sort key, 热数据放到ssd上等。
计算引擎
- 静态codegen
- 对于大多数的分布式计算系统,都喜欢用llvm来动态生成执行代码,以减少虚函数调用和分支跳转的开销。 但是llvm是有代价的,动态生成代码会带来毫秒级别的开销,对于Procella这样的系统,要求在几十毫秒内完成计算,动态codegen的overhead是不可接受的。同时由于他们的计算系统有个特点是大部分的query是固定的,比如前端显示的视频uv,pv等等。因此他们采用了静态编译的方式,通过c++ template来静态codegen,相当于枚举了所有的可能的operator。也算是一个特色吧。
- 这种方式缺点也很明显,静态codegen需要在编译时刻把所有代码编译出来,估计编出来binary会非常大,放到内存里边也会占用大量内存,还需要防止换出到swap。
- 以block为单元进行计算,block的大小不超过L1 cache,充分利用CPU的高速缓存。
- 代码上保证能够自动的向量化处理(simd)。
- 计算以encoding-native operator来计算。保证充分利用每一种encoding的计算优势,也避免数据反序列化的开销,同时也节省了内存使用。但是估计每个operator要是适配每一个encoding,代码工程量会不少。
- 谓词下推,减少scan的数据量,算是古老的加速手段了。
- metadata server 利用partitioning减少读取的文件,相当于谓词下推在partition上应用一层,过滤出只需要扫描的partition。
- 利用metadata的计算。
- 利用bloom filter & max/min信息 & 倒排索引以及其他的mta减少读盘计算。比如知道一个block的min/max之后,就可以根据filter条件确定是否要读取这个block。
Join
Join算是SQL里边的老大难题了,有很多算法来优化join的性能,比如RBO,CBO
Processla支持的join类型有
- broadcastjoin,广播式join,在大表join小表的场景,把小表复制到大表所在的每一个机器上,这样避免大表的复制。
- Co-partitioned join,左右表具有相同的partition信息,那么只把partition相同的数据hash到相同的机器,避免全量数据计算hash和跨机器拷贝。
- shuffle join, 左右表分别计算hash,hash值相同的数据shuffle到同一个机器上进行join,算是最慢的
- Pipelined join,如果右表是一个复杂的子查询,但是结果集合很小,那么倾向于先算出右表的结果,然后再按照broad cast join的方式。
- Remote Lookup ,如果dim table比较大,这个时候就不适合hash或者broadcast了,由于procella的存储格式支持高效的lookup,O(1)或O(logn)级别,因此可以通过rpc发起远程的lookup来完成join。
长尾query
在SQL/MapReduce任务中,最常见的一个难题是长尾query,由于局部计算过热导致影响整体的查询延时。
Procella提出了这些优化:
- Backup 策略
- 对于每一个data server上的计算都会统计其响应延时,并且汇总成分位,对于远大于均值的请求,认为是利群点,这个时候,启动备份的data server来重新计算这个任务。
- 限制发送到同一个ds的请求速度,前文讲过,processla是计算存储解耦的架构,但是为了充分利用缓存,又倾向于把同一份数据的计算调度到同一个机器上,因此这台机器又会成为热点。因此需要对发送到同一个ds的请求做资源限制。
- Smaller query具有高的优先级。 smaller query可以快速跑完,让出资源,因此procella倾向于让小query先跑。这和presto是相反的逻辑。presto倾向于让大query先跑,否则大query就饿死了。
Intermediate Merging
在merge节点,有些merge操作是单点的,因此会成为计算的瓶颈点。Procella采集一些统计信息,如果发现merge节点一段时间还未完成计算,那么就开启一些前置的线程进行分布式计算。预聚合的结果发送给merge算子。前置线程是在同一台机器上的,也避免了数据交换。
Query 优化器
静态优化器
静态优化器是指在plan阶段执行的优化逻辑,包括RBO,CBO。procella支持了RBO, filter pushdown, subquery decorrelation, constant folding等。
启发式优化器
Procella的一个特点就在于这个启发式的优化器,相对静态优化器而言,启发式优化器是在运行时执行的。启发式优化器通过采集计算的状态统计,例如统计数据,基数,distinct count,分位信息等。启发式优化器甚至可以在执行时修改物理执行计划。我们知道通常而言,SQL在plan阶段生成逻辑执行计划,经过优化后,再生成物理执行计划,物理执行计划下发到机器上后,就不再修改了。Procella做到了动态的修改plan。
主要又这几个优化点:
- 决定reduce的个数,例如,计算group by时,下游分配多少个节点是跟group by的key的基数相关的,因此可以统计基数信息,动态决定分配多少个reduce节点,甚至可以运行时取消部分reduce任务。
- 启发式agg:正式运行之前,在一份小的数据聚合上运行一下,获得结果和统计数据,评估输出的行数,决定分配多少个reduce节点。
- 启发是join:也是根据采样的数据评估哪种join方式比较合适。
- 启发式sort:sort避免不了全局排序,在全局做排序是非常消耗内存和CPU的事情,procella采集数据的分布信息,把全量数据分配到n个桶里边,Map阶段按照分位shuffle到下游节点,实现了桶排序。
当然启发式优化器是有代价的,需要先在采样的数据上跑一次,才能决定正式的执行计划。因此会带来一些overhead。procella提供了开关,可以关闭启发式优化器。不过对于用户而言,是非常乐意通过少量的overhead来换取很大的性能提升的。
Youtube内嵌statistics
内嵌指标就是我们通常在视频网站上看到的一些指标,比如视频多少人观看,多少人点赞等等。
针对这部分计算的需求有:
- 数据更新快。
- 请求的qps高。
- 查询要求毫秒级别。
为了应对上述需求,procella做了以下优化:
- 新数据写入存储的同时,也会写入ds内存中,以保证查询时命中内存。
- MDS作为ds的模块,以减少rpc调用。因为获取一些meta信息会向mds请求。而rpc的开销至少也是毫秒级别。
- metadata 预加载 & 异步增量同步,保证meta数据都在内存中。
- plan缓存在内存中。通常词法/语法解析,以及各种plan优化也会带来开销。针对内嵌场景,大量的query都是重复的,因此缓存下来可以节省不少CPU和延时。
- RPC合并发送。不同的server之间交互的时候,把rpc合并起来发送,以减少网络开销。
- 监控RS,DS的错误率,一旦达到阈值,把机器下线。
- 禁用启发式优化器,前边提到启发式优化器会带来一些开销,针对内嵌指标场景其实是没必要的。
总结
总结下来,procella做了很多方面的优化,以保证计算在毫秒级别完成,总体而言,这些优化手段可以归结为:
- 通过metadata减少读取磁盘的次数和大小。
- 通过encoding-native的方式让计算靠近数据,减少反序列化开销,也让encoding加速计算。
- 大量内存缓存的使用,使得procella完全变成了一个内存计算引擎。
- 启发式的优化器,动态优化执行计划。
参考资料
procella 论文